[摘要]在sql查询中为了提高查询效率,我们常常会采取一些措施对查询语句进行sql优化,下面总结的一些方法,有需要的可以参考参考。在某运营商的优化经历中曾经遇到了一条比较有意思的 SQL,具体如下:1 该最... 在sql查询中为了提高查询效率,我们常常会采取一些措施对查询语句进行sql优化,下面总结的一些方法,有需要的可以参考参考。在某运营商的优化经历中曾经遇到了一条比较有意思的 SQL,具体如下:1 该最开始的 sql 执行情况如下 SQL> SELECT
2 NVL(T.RELA_OFFER_SPEC_ID, SUBOS.SUB_OFFER_SPEC_ID) "offerSpecId"
3 FROM OFFER_SPEC_RELA T
4 LEFT JOIN OFFER_SPEC_GRP_RELA SUBOS
5 ON T.RELA_GRP_ID = SUBOS.OFFER_SPEC_GRP_ID
6 AND subos.start_dt <= SYSDATE
7 AND subos.end_dt >= SYSDATE
8 WHERE T.RELA_TYPE_CD = 2
9 AND t.start_dt <= SYSDATE
10 AND t.end_dt >= SYSDATE
11 AND (T.OFFER_SPEC_ID = 109910000618
12 OR EXISTS
13 (SELECT A.OFFER_SPEC_GRP_ID
14 FROM OFFER_SPEC_GRP_RELA A
15 WHERE A.SUB_OFFER_SPEC_ID = 109910000618
16 AND T.OFFER_SPEC_GRP_ID = A.OFFER_SPEC_GRP_ID
17 ))
18 AND rownum<500;
no rows selected
Execution Plan
----------------------------------------------------------
Plan hash value: 1350156609 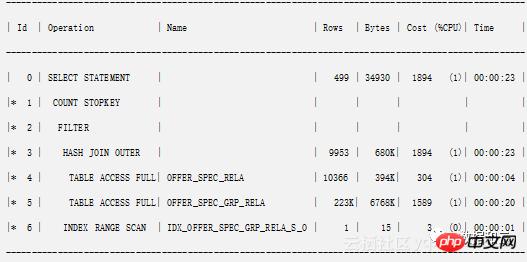
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter(ROWNUM<500)
2 - filter("T"."OFFER_SPEC_ID"=109910000618 OR EXISTS (SELECT 0 FROM
"SPEC"."OFFER_SPEC_GRP_RELA" "A" WHERE "A"."OFFER_SPEC_GRP_ID"=:B1 AND
"A"."SUB_OFFER_SPEC_ID"=109910000618))
3 - access("T"."RELA_GRP_ID"="SUBOS"."OFFER_SPEC_GRP_ID"(+))
4 - filter("T"."RELA_TYPE_CD"=2 AND "T"."END_DT">=SYSDATE@! AND
"T"."START_DT"<=SYSDATE@!)
5 - filter("SUBOS"."END_DT"(+)>=SYSDATE@! AND "SUBOS"."START_DT"(+)<=SYSDATE@!)
6 - access("A"."SUB_OFFER_SPEC_ID"=109910000618 AND "A"."OFFER_SPEC_GRP_ID"=:B1)
Statistics
----------------------------------------------------------
0 recursive calls
0 db block gets
12444 consistent gets
0 physical reads
0 redo size
339 bytes sent via SQL*Net to client
509 bytes received via SQL*Net from client
1 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
0 rows processed
PLAN GET DISK WRITE ROWS ROWS USER_IO(MS) ELA(MS) CPU(MS) CLUSTER(MS) PLSQL
END_TI I HASH VALUE EXEC PRE EXEC PRE EXEC PER EXEC ROW_P PRE EXEC PRE FETCH PER EXEC PRE EXEC PRE EXEC PER EXEC PER EXEC 
2 第一次分析
此时应该有以下个地方值得注意
1) 该 sql 每天执行上千次,平均每次执行返回不到 10 行数据,但是平均逻辑读达到1.2W,可能存在性能问题。
2)ID 为 4,5 的执行计划路径中出现了两个全表扫描,看到这儿我们可以想到可能是没有合适的索引导致走了全表扫描从而执行效率低下。
3)ID 为 2 的执行计划路径出现了 FILTER,且 3,和 6 为其子路径,如果FILTER有两个及两个以上的子路径,那么他的执行原理将类似于嵌套循环,id 号最小的子路径如果返回行数较多,可能会导致多次执行id号更小的子路径,导致性能低下。一般存在 “OR EXISTS” 的时候会出现此情况,可以根据情况避免。 相关链接:
PHP-FPM实现性能优化,php-fpm性能优化 【SQL】MySQL性能优化_MySQL MySQL优化视频教程 以上就是SQL优化:很简单的一篇提高SQL性能的文章!的详细内容,更多请关注php中文网其它相关文章!
学习教程快速掌握从入门到精通的SQL知识。
|
关键词: SQL优化:很容易的一篇提高SQL性能的文章!