mysql的索引底层之完成原理
时间:2024/2/27作者:未知来源:盘绰网教程人气:
- [摘要]MySQL索引背后的数据结构及算法原理一、定义索引定义:索引(Index)是帮助MySQL高效获取数据的数据结构。本质:索引是数据结构。二、B-Treem阶B-Tree满足以下条件:1、每个节点至多...MySQL索引背后的数据结构及算法原理
一、定义
索引定义:索引(Index)是帮助MySQL高效获取数据的数据结构。
本质:索引是数据结构。二、B-Tree
m阶B-Tree满足以下条件:
1、每个节点至多可以拥有m棵子树。
2、根节点,只有至少有2个节点(要么极端情况,就是一棵树就一个根节点,单细胞生物,即是根,也是叶,也是树)。
3、非根非叶的节点至少有的Ceil(m/2)个子树(Ceil表示向上取整,如5阶B树,每个节点至少有3个子树,也就是至少有3个叉)。
4、非叶节点中的信息包括[n,A0,K1,A1,K2,A2,…,Kn,An],,其中n表示该节点中保存的关键字个数,K为关键字且Ki<Ki+1,A为指向子树根节点的指针。
5、从根到叶子的每一条路径都有相同的长度(叶子节点在相同的层)B-Tree特性:
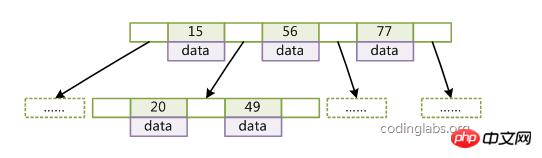
1、关键字集合分布在整颗树中;
2、任何一个关键字出现且只出现在一个节点中;
3、每个节点存储date和key;
4、搜索有可能在非叶子节点结束;
5、一个节点中的key从左到右非递减排列;
6、所有叶节点具有相同的深度,等于树高h。B-Tree上查找算法的伪代码如下:

三、B+Tree
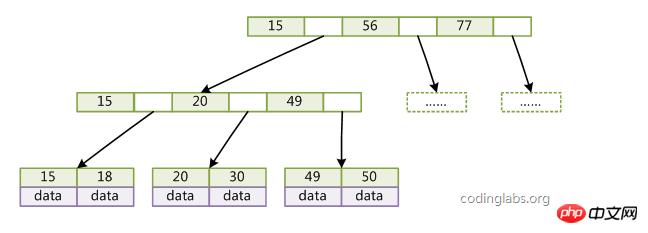
B+Tree与B-Tree的差异在于:
1、B+Tree非叶子节点不存储data,只存储key;
2、所有的关键字全部存储在叶子节点上;
3、每个叶子节点含有一个指向相邻叶子节点的指针,带顺序访问指针的B+树提高了区间查找能力;
4、非叶子节点可以看成索引部分,节点中仅含有其子树(根节点)中的最大(或最小)关键字;四、B/B+树索引的性能分析
依据:使用磁盘I/O次数评价索引结构的优劣
主存和磁盘以页为单位交换数据,将一个节点的大小设为等于一个页,因此每个节点只需一次I/O就可以完全载入。
根据B树的定义,可知检索一次最多需要访问h个节点
渐进复杂度:O(h)=O(logdN)
dmax=floor(pagesize/(keysize+datasize+pointsize))
一般实际应用中,出度d是非常大的数字,通常超过100,因此h非常小(通常不超过3,3层可存大约一百万数据)
B-Tree中一次检索最多需要h-1次I/O(根节点常驻内存)
B+Tree内节点不含data域,因此出度d更大,则h更小,I/O次数少,效率更高,故B+Tree更适合外存索引。五、MySQL索引实现
1、MyISAM引擎使用B+Tree作为索引结构,叶节点的data域存放的是数据记录的地址;
MyISAM主索引和辅助索引在结构上没有任何区别,只是主索引要求key是唯一的,而辅助索引的key可以重复;2、InnoDB的数据文件本身就是索引文件,叶节点包含了完整的数据记录,这种索引叫做聚集索引。
因为InnoDB的数据文件本身要按主键聚集,所以InnoDB要求表必须有主键(MyISAM可以没有),如果没有显式指定,则MySQL系统会自动选择一个可以唯一标识数据记录的列作为主键,如果不存在这种列,则MySQL自动为InnoDB表生成一个隐含字段作为主键。
InnoDB的辅助索引data域存储相应记录主键的值而不是地址;
辅助索引搜索需要检索两遍索引:首先检索辅助索引获得主键,然后用主键到主索引中检索获得记录;3、页分裂问题
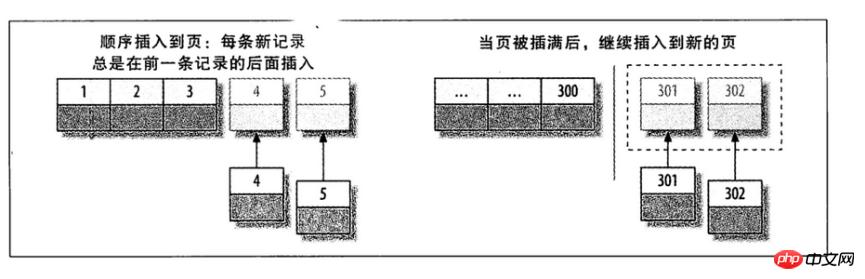
如果主键是单调递增的,每条新记录会顺序插入到页,当页被插满后,继续插入到新的页;
如果写入是乱序的,InnoDB不得不频繁地做页分裂操作,以便为新的行分配空间。页分裂会导致移动大量数据,一次插入最少需要修改三个页而不是一个页。
如果频繁的页分裂,页会变得稀疏并被不规则地填充,所以最终数据会有碎片。
六、总结
了解不同存储引擎的索引实现方式对于正确使用和优化索引都非常有帮助
1、为什么不建议使用过长的字段作为主键?
2、为什么选择自增字段作为主键?
3、为什么常更新是字段不建议建立索引?
4、为什么选择区分度高的列作为索引?区分度的公式是count(distinct col)/count(*)
5、尽可能的使用覆盖索引
七、优化LIMIT分页查询
上述SQL语句的实现机制是:
1、从“table”表中读取offset+rows行记录。
2、 抛弃前面的offset行记录,返回后面的rows行记录作为最终的结果。
覆盖索引:八、Q&A
1、InnoDB支持hash索引吗?--马欣
InnoDB是支持hash索引的,不过其支持的hash索引是自适应的,InnoDB存储引擎会根据表的使用情况自动为表生成hash索引,不能人为干预是否在一张表中生成hash索引。
2、InnoDB主键索引的叶节点含完整的数据记录,那主键索引文件要比数据文件大吗?--徐财厚
1).在Innodb 引擎中,主键索引中的叶子结点包含记录数据,主键索引文件即为数据文件。
2).在 tables 表中统计的data_length数据为主键索引大小,index_length 为统计的这个表中所有辅助索引(二级索引)索引的大小。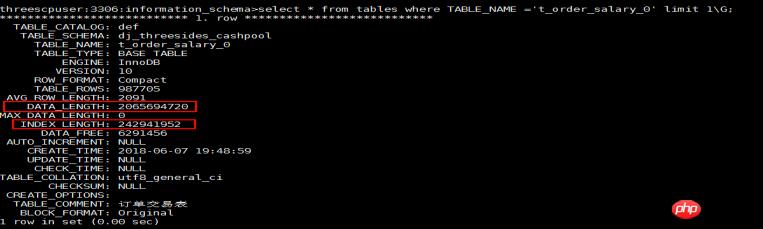
以上就是mysql的索引底层之实现原理的详细内容,更多请关注php中文网其它相关文章!
学习教程快速掌握从入门到精通的SQL知识。关键词: mysql的索引底层之完成原理